HTTP: de basis voor interactie
HTTP is het stille jongetje in de hoek van een klas vol met aansprekende technologie zoals CSS, Javascript en Ruby on Rails. Het is echter een essentieel onderdeel van de gebruikersinteractie op een website: waar HTML en CSS de objecten in een website beschrijven, vertelt HTTP wat we met de objecten kunnen doen.
 Jeroen Pulles
5 juni 2008
Jeroen Pulles
5 juni 2008
Dit artikel verscheen eerder in Naar Voren, Tijdschrift voor webwerkers
HTTP (Hypertext Transfer Protocol) is het protocol waarmee webpagina’s van de webserver naar de browser worden verstuurd. Iedereen heeft ermee te maken, maar ik merk dat dit onderwerp wel eens tussen wal en schip belandt, of anders gezegd, tussen front-end en back-end ontwikkelaar.
Aan de hand van een simpel voorbeeldscenario zal ik duidelijk maken waarom het protocol zo belangrijk is. Een simpel voorbeeld om dicht bij de essentie te blijven: hoe kies ik de juiste HTTP-instructies. Om dezelfde reden is er ook geen voorbeeldcode: ik denk dat er weinig verbeelding voor nodig is om dit voorbeeld te vertalen naar werkende code.
Krabbel, een notitie-applicatie
Stel dat we een kleine applicatie maken waarmee we notities aan een agenda kunnen toevoegen. De applicatie noemen we Krabbel. Krabbel maakt deel uit van een grotere website met op iedere pagina vaste navigatie naar alle hoofdelementen van de site.
Krabbel bestaat voor de eenvoud van het voorbeeld uit slechts twee functies, ‘Schrijf notitie’ en ‘Bekijk notitie’. Bij de twee functies horen ook twee templates. Om de notitie in te voeren is er een template met een formulier. Nadat de notitie is geschreven, wordt de notitie automatisch getoond in dezelfde template als ‘Bekijk notitie’.
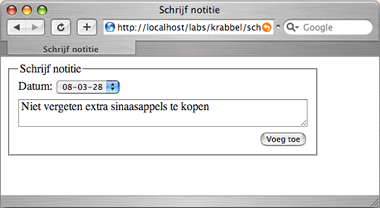
Schrijf notitie
Op /krabbel/schrijf staat de pagina met het formulier om
een notitie aan de agenda toe te voegen. Het formulier heeft twee velden:
een dropdown met de datum en een tekstveld voor de notitie.
De bezoeker kiest de datum en schrijft een notitie „Niet vergeten extra sinaasappels te kopen”. De bezoeker klikt op de knop ‘Voeg toe’ onderaan het formulier.
Het formulier wordt nu verstuurd naar de server.
Browsers bieden de ontwikkelaar twee manieren om de gegevens naar de
webserver te sturen: GET en POST, twee zogenaamde
HTTP methodes. Een methode is een aanduiding wat de webserver moet
doen met het document (beter gezegd: resource) op de URL waarnaar wordt
verwezen. In het method attribuut van het
<form>
element kunnen we aangeven of de gegevens middels een ‘get’ of een
‘post’ moeten worden verstuurd.
Nu stuiten we op onze eerste ontmoeting met een keuze in het gebruik van het HTTP-protocol. Als we met een GET het formulier zouden versturen, dan zouden we in de URL het ingevulde formulier te zien krijgen:
/krabbel/schrijf?dag=08-03-28¬itie=Niet+vergeten+extra+sinaasappels+te+kopen
Hoewel dit technisch prima mogelijk is, is het geen mooie oplossing. Het is net alsof we een adres op een envelop schrijven en daar meteen maar de boodschap bij schrijven, in plaats van de boodschap in de envelop te stoppen. De ingevoerde data is nu plotseling zichtbaar in de logs van de webserver en misschien ook wel in de logs van de bezoekersteller. Je kunt als richtlijn aanhouden dat je data waarmee je de inhoud van de site wijzigt niet in een GET verstuurt, maar altijd in een POST of een PUT.

Het analoge equivalent van een formulier in een GET request
We kiezen er dus voor om het formulier met een POST te versturen naar
de URL /krabbel/schrijf. Achter die URL zit een script dat
de opgestuurde data kan verwerken. Dat kan in iedere programmeertaal,
bijvoorbeeld PHP.
Krabbel doet verder niet veel bijzonders. Het controleert even of de ingevoerde datum een valide datum is, controleert of er geen HTML-code in de notitie staat en voegt de notitie vervolgens aan de database van de webserver toe. De database weet daarna te vertellen dat de nieuwe notitie een uniek nummer heeft gekregen waarmee de notitie weer opgehaald kan worden, laten we zeggen ‘42’.
De webserver is nu klaar met de verwerking van het formulier en wil de bezoeker een pagina tonen met de ingevulde notitie. In veel back-end omgevingen is het dan vanzelfsprekend om direct na de wijziging in de database de ingevulde data te renderen in de HTML template en die webpagina naar de browser terug te sturen. Daarbij lopen we echter tegen twee vervelende problemen aan.
Ten eerste wordt de notitie getoond in de browser op de URL
/krabbel/schrijf.
De bezoeker is wellicht heel blij met zijn notitie en denkt later de notitie nog een keer te willen bekijken. De bezoeker maakt een bookmark aan. De volgende dag komt hij terug op de bookmark, ontdekt dat de notitie weg is en dat er een leeg ‘Schrijf een notitie’- formulier wordt getoond.
De browser heeft namelijk geen notitie-gegevens meegestuurd, waardoor de webserver denkt dat hij het formulier moet tonen. De browser onthoudt dat de pagina is getoond na het posten van een formulier. Daarmee stuiten we (vaak) op een tweede probleem;
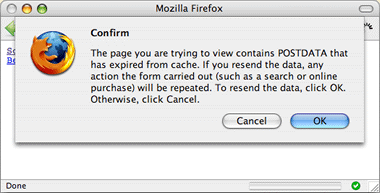
Firefox 2-melding bij gebruik van de Terug-knop naar een verlopen pagina.
De bezoeker navigeert weg van de notitiepagina door op de link naar de homepage te klikken. Daarna wil hij weer teruggaan naar de notitiepagina en klikt op de Terug-knop. De browser toont vervolgens echter een waarschuwingsdialoog waarin wordt gezegd dat de pagina is verlopen. De bezoeker wordt gevraagd of het formulier opnieuw moet worden opgestuurd. In dit geval is het juiste antwoord „Nee, niet opnieuw opsturen”. De bezoeker kan echter niet weten wat het juiste antwoord is. Je moet weten hoe de applicatie werkt om te begrijpen wat wel of niet een goed idee is. Als in dit voorbeeld het formulier opnieuw zou worden opgestuurd, dan zou er een tweede notitie met dezelfde inhoud worden gemaakt.
Veel websites zijn zodanig geconfigureerd dat de pagina’s die worden gegenereerd door een programmeertaal niet worden gecached door de webbrowser. Vaak wordt er een Expires header meegestuurd waarin staat de pagina is verlopen op het moment dat de browser de pagina leest. Ik ga er even vanuit dat dit in dit voorbeeld het geval is. Out-of-the box heb je hier meestal geen probleem mee. Dit probleem treedt meestal pas op als de ontwikkelaar met brute kracht caching van content probeert te voorkomen. Helaas gebeurt dat regelmatig. Over het effectief cachen van content en conditional GET’s zou je een compleet boek kunnen schrijven [Boeken].
Een header is een klein stukje metadata bij de pagina die wordt verstuurd. Een bekende header is Content-Type, die aangeeft wat voor type document een pagina is.
Als we toch hadden gekozen voor een GET om het formulier op te sturen, dan hebben we nu waarschijnlijk twee dezelfde notities.
Redirect
De oplossing voor beide problemen is het gebruik van een redirect. Het
is een goed gebruik om na het aanmaken van een nieuwe resource (een notitie
in ons geval) de browser naar de URL voor die nieuwe resource te sturen. Zo
zal Krabbel tegen de browser zeggen „Ga naar
/notitie/42”. Omdat alles goed is gegaan, kiezen we in
het antwoord van de webserver voor een HTTP status code uit de 200-reeks,
namelijk ‘201 Created’, wat aangeeft dat er een nieuwe pagina
(resource) is aangemaakt op de webserver.
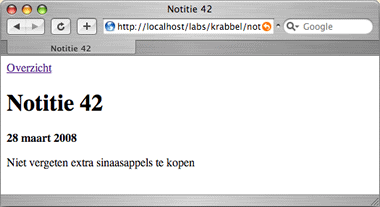
Bekijk notitie
De browser volgt de instructie van de webserver op en haalt vervolgens
de notitie op van URL /notitie/42. Daar staat het tweede
deel van de functionaliteit van Krabbel. De webserver haalt uit de database
de notitie met ID 42, stelt een webpagina samen met de notitie daarin en
stuurt die terug naar de browser. Nu hebben we een URL waar de notitie
altijd bekeken kan worden en veilig gebookmarkt kan worden.
Een bijkomend voordeel is dat de twee URL’s ook ieder een eigen
template houden. De pagina /krabbel/schrijf heeft een template met het
invulformulier, /notitie/{id} heeft een template om de
notitie te tonen.
Moet je nu altijd een redirect sturen na het opsturen van een formulier? Nee, de redirect is alleen bedoeld om aan te geven dat er een nieuwe resource op de webserver is aangemaakt. Dat voorkomt dat dezelfde notitie op meerdere URL’s getoond wordt, zodat je bijvoorbeeld geen probleem met bookmarken ondervindt. Het omzeilen van de verlopen cache is een neveneffect. Het tweede probleem met de verlopen cache had ook opgelost kunnen worden door de juiste headers mee te sturen (of de verkeerde headers weg te laten).
Wat te doen als de bezoeker foutieve data naar de webserver stuurde bij het aanmaken van de notitie? De webserver zal een foutmelding bij het formulier terugsturen samen met de correct invulde data. Hier wordt geen redirect gebruikt.
In schematische weergave ziet deze kleine actie om een notitie toe te voegen in onze applicatie er dan als volgt uit:
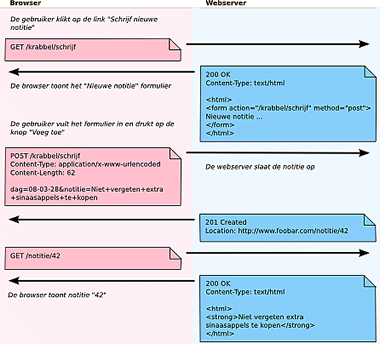
Schematische weergave van de stappen in Krabbel (SVG illustratie [27KB])
![SVG illustratie [27KB]](media/krabbel-protocol-plain.svg){kind=link}
Tenslotte
Hopelijk maakt dit kleine voorbeeld duidelijk dat zelfs als een applicatie bestaat uit een aantal simpele stappen er een aantal belangrijke keuzes worden gemaakt in de interactie tussen browser en server. Ik wil zelfs beweren dat de webby-ness van een applicatie, naast templates, voor een belangrijk deel wordt bepaald door je keuzes in HTTP-instructies.
Moet je die keuzes nog wel zelf maken? Er begint meer aandacht voor dit onderwerp te komen in frameworks. De scaffolding code van Ruby on Rails zet al een complete set van URL’s klaar om resources aan te maken, te wijzigen en te verwijderen.
Veel lower-level frameworks maken echter geen onderscheid tussen formuliergegevens in de (GET) query string of in (POST) message bodies. Java’s HttpServletRequest is een notoir voorbeeld hiervan. Als de front-end developer de methode in een formulier ook open laat, kiest hij impliciet voor een GET request. Front-end en back-end developer zullen in zo’n geval samen tot een afspraak moeten komen. En zo zijn er veel meer aspecten die deze frameworks open laten.
Zijn er goede voorbeelden van het gebruik van HTTP in complexere applicaties? Er zijn weinig beschrijvingen van toepassingen van het HTTP protocol buiten de webservices-wereld. De Atom Publishing specificatie is redelijk helder en, alhoewel in eerste instantie niet direct bedoeld voor webbrowsers, tot op zekere hoogte te vertalen naar gebruik in gewone webapplicaties.
Is dit ook van toepassing in AJAX en SPI situaties? In zekere zin heb je met AJAX meer vrijheid en hoef je je minder van de browser aan te trekken. Toch blijven veel van de regels voor HTTP gelden.
Gebruik eens een proxy tussen je webbrowser en de webserver als je wilt weten hoe jouw favoriete webapplicatie de interactie tussen browser en webserver oplost. Proxies zoals Fiddler en Charles kunnen op een prettige manier visueel tonen welk verkeer tussen de browser en server heen en weer gaat [Links]. Firebug toont ook wat er gebeurt, maar kan requests niet naspelen of aanpassen. Het gebruik van een debugging proxy is ook essentieel als je wilt weten wat er onder water gebeurt bij bijvoorbeeld AJAX calls.
RFC 2616 Hypertext Transfer Protocol -- HTTP/1.1 specificeert het protocol; Oplettende lezers zien al snel dat bovenstaand voorbeeld een uitwerking is van sectie 9.5 POST;
Meer te weten komen over HTTP uit een boek? Gedegen kost is Web Protocols and Practice door Balachander Krishnamurthy en Jennifer Rexford. Toegankelijker en meer toegepast is RESTful Web Services door Leonard Richardson en Sam Ruby;
Een voorbeeld van een HTTP toepassing is RFC 5023: The Atom Publishing Protocol; Hoofdstuk 5, Protocol Operations;
Meer te weten komen over het verkeer tussen browser en webserver? Gebruik proxy software zoals Fiddler (alleen voor Internet Explorer) en Charles of gebruik bijvoorbeeld de Firebug extensie voor Firefox.